AMD GPU上的AI大模型部署指南:从ROCm环境搭建到Ollama本地推理实战
AMD 在 CPU 和 GPU 市场已深耕多年。在处理器领域,AMD 不仅与英特尔形成有效竞争,近期在数据中心市场份额方面甚至实现了超越。而在 GPU 领域,尽管 AMD 主要聚焦于中端游戏市场,提供了一系列性价比优异的高性能显卡,但在 AI 计算特别是 LLM 推理方面,专业技术文档与实施指南相对匮乏,这制约了开发者充分利用 AMD 硬件进行 AI 开发。

本文以 AMD Radeon RX 7900XT 为例,RX 7900XT 配备 5376 个流处理器(与 CUDA 核心在概念上相似但架构不同)和 20GB GDDR6 显存(320 位总线宽度)。我们将在 Linux 环境下解决了 ROCm 部署的诸多技术挑战。
系统架构与环境配置本文采用的 LLM 部署架构基于 ROCm + Ollama + Open WebUI 技术栈以下配置步骤会因目标平台特性(如操作系统版本)而略有差异。本文主要以Linux 环境为例,适用于大多数基于 Ubuntu/Debian 的发行版。对于其他 Linux 发行版,请参考相应的软件包管理与系统配置命令。
1、GPU 驱动与 ROCm 环境配置安装 GPU 驱动是硬件升级后的首要任务。除了基本显卡驱动外,还需要安装 AMD 的 Radeon Open Compute Platform (ROCm),这是 Ollama 在 GPU 上执行推理任务的基础环境,类似于 NVIDIA 的 CUDA 平台。
首先,需确定 ROCm 版本与 GPU 型号及 Linux 内核的兼容性。可通过以下命令查看当前内核版本:
测试结果表明,随着模型参数量增加,推理性能呈现明显下降趋势。对比 NVIDIA 硬件,RTX 5090 在 deepseek-r1:14b 模型上可达到约 122 tokens/秒的性能,远高于本文中测试的 AMD 显卡(43 tokens/秒)。然而,考虑到价格因素(RX 7900XT 约 700 欧元,而 RTX 5090 超过 2200 欧元),AMD 方案在性价比方面仍具有显著优势。从用户体验角度,任何超过 30 tokens/秒的推理速度已足以支持流畅的交互体验。
用户界面与实际应用Open WebUI 提供了直观的操作界面。以下示例演示了使用 qwen2.5-coder:14b 模型作为数据科学辅助工具的实际场景,推理吞吐量约为 38 tokens/秒:
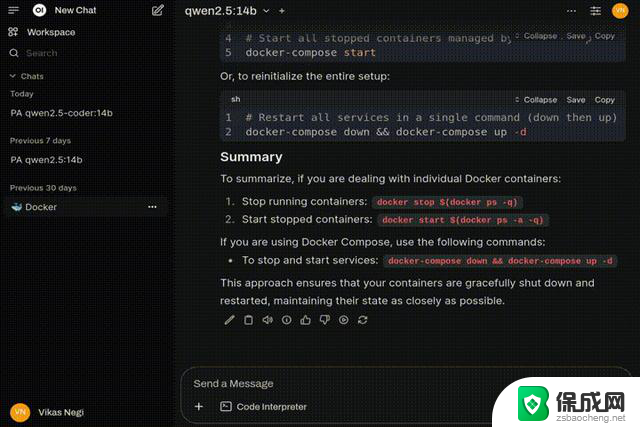 高级配置与优化模型管理与下载
高级配置与优化模型管理与下载系统支持便捷的模型搜索与下载功能,可根据需求扩展本地模型库:
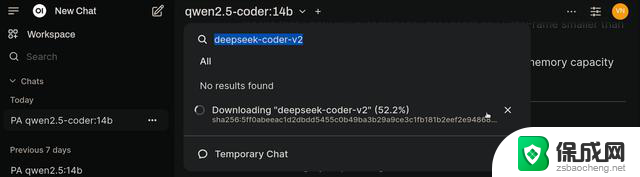 系统提示与参数调优
系统提示与参数调优通过右上角的 Chat Controls(聊天控制)设置,可自定义系统提示,优化模型输出:
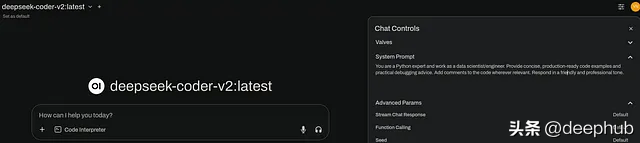 GPU 计算层配置
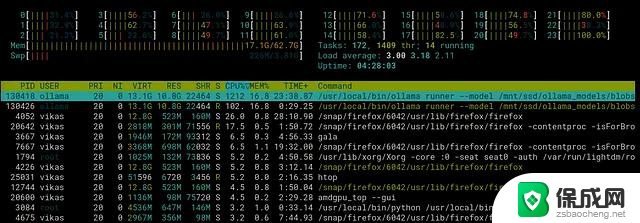
GPU 计算层配置在同一设置面板底部的 num_gpu 参数可调整卸载到 GPU 的计算层数,影响性能与资源使用:

当 num_gpu 设置为 0 时,系统将完全依赖 CPU 执行推理计算。虽然这可能在功耗方面更为高效,但性能会有显著下降。如 deepseek-coder-v2 模型在 CPU 模式下仅能达到 12 tokens/秒,而 GPU 模式可达 60 tokens/秒:
 总结
总结在 AMD 硬件上构建 LLM 推理环境目前仍面临一定技术挑战,尚未达到 NVIDIA CUDA 生态系统的即插即用水平。本文所述的工具链和配置方法,完全可以将现有的 AMD 游戏显卡转化为高效的 AI 推理设备。这种方案不仅在经济性上更具优势,还有助于推动 AI 硬件生态系统的多元化发展。
随着 AMD 持续完善 ROCm 平台,以及开源社区对非 NVIDIA 硬件的支持不断增强,基于 AMD GPU 的本地 LLM 部署方案将获得更广泛的应用。在 AI 技术日益普及的今天,能够在本地硬件上高效运行大型语言模型,为个人用户和小型组织提供了一种经济可行且不依赖云服务的 AI 实践路径。
作者:Vikas Negi